《A Comprehensive Survey of Continual Learning:Theory, Method and Application》论文阅读
论文:A Comprehensive Survey of Continual Learning:Theory, Method and Application
除此之外,近年来出现了越来越多持续学习的进步,这些进步大大拓展了我们对持续学习的理解和应用。
这个方向日益增长和广泛的兴趣表明了它的现实意义和复杂性。
在这项工作中,我们提供了一项关于持续学习的全面调查,旨在连接基本设置、理论基础、代表性方法和实际应用。
这篇论文是第一项系统总结持续学习最新进展的调查。在此基础上,我们对持续学习的当前趋势、扩散模型、大规模预训练、视觉变换器、嵌入式人工智能、神经压缩等横向前景进行了深入的讨论,以及与神经科学的跨学科联系。
持续学习
要应对现实世界的动态变化,一种智能体需要在其一生中逐步获取、更新、积累并利用知识。这种能力被称为持续学习(continual learning),为人工智能系统自适应发展提供了基础。
灾难性遗忘
一般来说,持续学习明显受到灾难性遗忘(catastrophic forgetting)的限制,即学习新任务通常会导致旧任务的性能大幅下降。
这种困境是学习可塑性和记忆稳定性之间权衡的一个方面:前者的过度会干扰后者,反之亦然。
持续学习概念框架
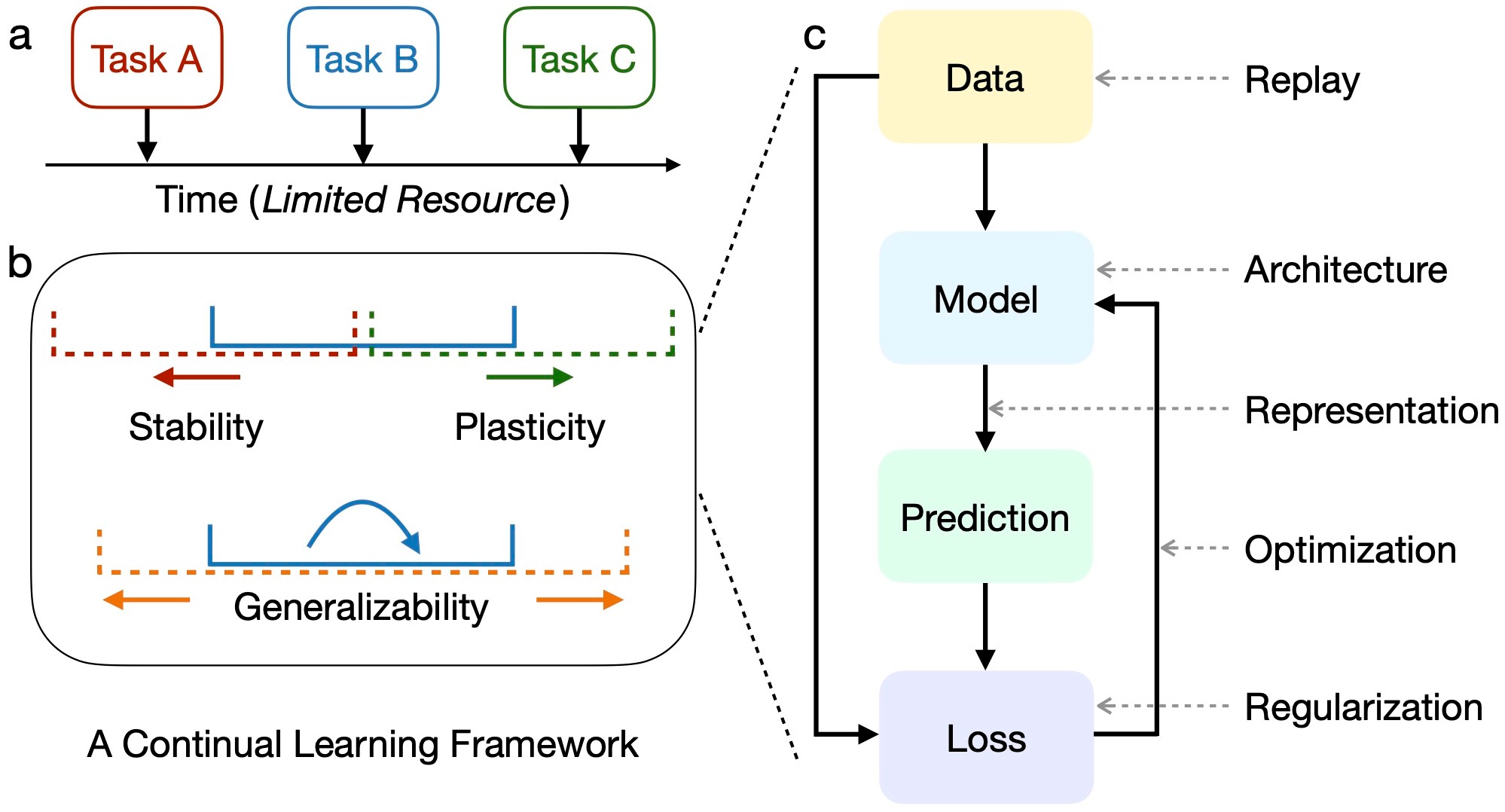
这幅图解释了持续学习机器学习模型的一个概念性框架。
顶部显示了三个连续的任务A、B、C,它们共享一个有限的时间资源,代表模型需要在有限时间内适应不断增加的新任务。
下半部分的椭圆形框架描述了一个理想的持续学习解决方案应该具备的三个重要特性:
- 稳定性(stability):确保模型在学习新知识时不会完全遗忘旧有知识。
- 可塑性(plasticity):使模型有能力学习新的知识和技能。
- 泛化能力(generalizability):使模型能够应对同一任务和不同任务中的数据分布变化。
这三个特性需要平衡权衡。
右侧展示了机器学习模型的典型组件,持续学习策略可针对这些部分进行优化和调整,如利用回放(replay)技术保护旧数据,调整模型架构和表示形式,以及应用正则化(regularization)等优化目标。
五种方法
为了解决上述挑战,人们做出了许多努力,这些挑战在概念上可以分为五组:
- 参考旧模型添加正则化项(基于正则化的方法);
- 近似并恢复旧的数据分布(基于重放的方法);
- 显式操作优化程序(基于优化的方法);
- 学习稳健且通用的表示(基于表示的方法);
- 通过适当设计的架构(基于架构的方法)构建任务自适应参数。
该分类法通过最新进展扩展了常用的分类法,并为每个类别提供了细化的子方向。我们总结了这些方法如何实现所提出的总体目标,并对其理论基础和典型实现进行了广泛分析。特别是,这些方法紧密相连,例如,正则化和重放最终用于纠正优化中的梯度方向,并且高度协同,例如,可以通过从旧模型中提取知识来促进重放的功效。
数学符号表示
持续学习是指机器学习模型在遇到新的任务时,能够增量学习新知识,同时不会过多遗忘之前学习的内容。不同场景对应模型面临的数据分布和任务顺序等条件有所区别。
首先理解一些符号:
- Dt,b: 第t个任务的第b批训练样本
- |b|: 第b批样本的大小
- Bt: 第t个任务的所有批次样本集合
- Dt: 第t个任务的整个训练集(也表示为Dt^tr用于预训练)
- T: 所有增量任务的集合(也表示为T^tr用于预训练)
- Xt: 第t个任务的输入数据
- p(Xt): Xt的数据分布
- Yt: Xt对应的数据标签
基本公式
持续学习是从动态数据分布中学习的过程。在实践中,来自不同分布的训练样本会依次到来。一个持续学习模型需要学习相应的任务,同时无法或只能有限地访问旧的训练样本,但在相应任务的测试集上表现良好。形式上,属于任务t的一批训练样本可以表示为{(x,y)},其中x是输入数据,y是数据标签,t是任务身份,b是批次索引。我们根据样本的分布p(x,y)来定义一个"任务"。我们假设训练集和测试集的分布相同。在现实约束下,数据标签y和任务身份t可能无法获得。在持续学习中,每个任务的训练样本可以分批次增量到来,也可以同时到来。
形式上,属于任务t的一批训练样本表示为
一个"任务"t由其训练样本
在现实约束下,
每个任务训练样本可以分批次增量到来
典型场景
| 场景 | 英文 | 缩写 | 说明 |
|---|---|---|---|
| 实例增量学习 | Instance-Incremental Learning | IIL | 所有训练数据都属于同一个任务,只是训练数据一批批到达,而非一次性获得全部数据。 |
| 领域增量学习 | Domain-Incremental Learning | DIL | 虽然任务目标相同(如分类),但输入数据的分布不尽相同,系统需要适应新的数据分布。无需指定任务类型。 |
| 任务增量学习 | Task-Incremental Learning | TIL | 系统需要学习多个不同的任务,每个任务的目标标签空间都不相交。训练和测试时,需要指定当前任务类型。 |
| 类增量学习 | Class-Incremental Learning | CIL | 类似任务增量学习,但在测试时不提供任务类型信息,系统需自行判断当前任务。 |
| 无任务持续学习 | Task-Free Continual Learning | TFCL | 任务之间没有明确界限,目标标签集可能会重叠,且不提供任务类型信息。系统需同时处理所有可能的任务。 |
| 在线持续学习 | Online Continual Learning | OCL | 与无任务持续学习类似,但训练数据是一次性流式到达,无法重复利用之前的数据。系统必须在线学习。 |
| 模糊边界持续学习 | Blurred Boundary Continual Learning | BBCL | 不同任务的目标标签集会有一定重叠。系统需识别出不同的任务,并正确处理重叠部分。 |
| 持续预训练 | Continual Pre-training | CPT | 对大规模预训练模型持续做预训练,以提高其在下游任务上的表现。预训练数据是一点点到来的。 |
评价指标
持续学习的表现可以从三个方面来评估:
- 迄今为止所学任务的整体表现
- 旧任务的记忆稳定性
- 新任务的学习可塑性
基于重放提升稳定性
一个简单的想法是通过存储一些旧的训练样本或训练生成模型来近似和恢复旧的数据分布,称为基于重放的方法。
根据监督学习的学习理论,旧任务的性能可以通过重放更多接近其分布的旧训练样本来提高,但存在潜在的隐私问题和资源开销的线性增加。
生成模型的使用还受到巨大的资源开销以及它们自身的灾难性遗忘和表达能力的限制。
持续学习是 NP-Hard
continual learning(持续学习)这个问题的难度:
持续学习指的是机器学习模型在学习新任务的同时,不会忘记旧任务已经学到的知识。实现这个目标很困难,因为它相当于在一个有限的参数空间中同时学习所有新旧任务,使得所有任务的性能都不会下降。
文中提到这个continual learning问题是NP-Hard问题。NP-Hard意味着这个问题是非常困难的,目前没有已知的有效算法可以在合理时间内解决。之所以是NP-Hard,是因为随着新任务不断增加,可行的参数空间会变得越来越狭窄和不规则,很难找到一个能同时适用于所有任务的最优解。
作者提出了一些缓解这个问题的方法:
- 重复学习部分旧任务的训练样本
- 将可行解的参数空间限制在一个超矩形区域内
- 放弃使用单个参数空间,改用多个持续学习模型
通过这些方法,可以在一定程度上缓解continual learning问题的困难,但总的来说这仍是一个极具挑战的问题。
正则化
在持续学习中用于权衡新旧任务的正则化(Regularization-based Approach)方法。正则化的目的是在学习新任务的同时,尽量保留之前学到的旧知识,避免完全遗忘。
正则化方法主要分为两大类:
这类方法对神经网络参数(权重)的变化加以限制,使其在学习新任务时不能改变太多。常见做法是在损失函数中加入一个惩罚项,惩罚每个权重变化的幅度。惩罚程度由该权重对旧任务的重要性决定 - 越重要,惩罚越大。
计算权重重要性的方法有很多种,比如利用Fisher信息矩阵、跟踪权重变化对总损失的影响等。一些改进版本尝试更精确地估算权重重要性。
除了惩罚项的设计,还有工作聚焦于如何更好地近似Fisher信息矩阵。
这类方法直接限制神经网络的中间输出或最终预测输出,使其不偏离之前学到的函数。
常见做法是[000.wiki/知识蒸馏|知识蒸馏] - 将新模型的输出要尽量接近旧模型的输出。理想情况下蒸馏目标应该是全部旧任务数据,但实际上通常无法获得。取而代之的是新数据预测、少量旧数据、无标签数据、生成数据等,存在一定分布偏移。
除了显式蒸馏,一些基于贝叶斯框架的方法也能实现一种函数正则化,但需要存储少量旧数据。
对于生成任务,则约束新旧模型对已学习条件的数据生成结果保持一致。
总的来说,正则化方法都是在学习新任务时,施加一些约束,使模型在获取新知识的同时尽量保留旧知识,权衡稳定性和可塑性。
重放
好的,我尽量用通俗易懂的语言为你解释一下这部分内容。
这里讨论了三种基于Replay(重放)的方法,用于在持续学习中估计和恢复旧的数据分布。
第一种是经验重放(experience replay),它在小型缓冲区中存储少量旧的训练样本。由于存储空间极其有限,主要挑战在于如何构建和利用这个缓冲区。
构建时,需要仔细选择、压缩、增强和不断调整存储的训练样本,以最大化从中恢复过去信息的能力。早期工作采用固定原则进行样本选择,如随机保留、按类别平均保留等。后来的策略更加高级,通过优化目标如样本多样性、任务性能、鲁棒性等来选择样本。
为提高存储效率,一些方法对旧样本进行压缩或数据增强。在利用时,一些工作通过限制旧样本的作用防止catastrophic forgetting,另一些与知识蒸馏(knowledge distillation)相结合。
第二种是生成重放(generative replay),需训练额外的生成模型产生样本。它与持续学习生成模型自身密切相关。主流方法基于GAN和VAE,但GAN可能产生标签不一致的样本,VAE则生成质量较差。
第三种是特征重放(feature replay),直接在特征层面而非数据层面估计和恢复分布,效率更高且无隐私风险。但需应对由于不断更新特征提取器导致的表示偏移(representation shift)问题。一些工作通过特征蒸馏、保存统计信息或训练生成模型等方式应对此问题。利用预训练模型的鲁棒表示可以缓解表示偏移。
总的来说,这三种重放方法通过不同方式估计和恢复旧的数据或特征分布,是持续学习中一类重要的方法,但各自也面临一些挑战有待解决。
本文作者:Maeiee
本文链接:《A Comprehensive Survey of Continual Learning:Theory, Method and Application》论文阅读
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
